Apart from a program that is being executed there is always one more (system) program permanently stored in primary memory. This is called the operating system. This is the program (or set of programs) that is always running when no "ordinary" program is being run. Operating systems are advanced pieces of software provided by the manufacturers of computer systems. We say that a particular computer system "runs under" a certain operating system. Computers are designed to put the operating system directly into operation when the computer is "switched on". The operating system (amongst other things):
Usually user commands are passed to the the computer using the keyboard (alternatively some operating systems support communication via the mouse). Typical commands supported by operating systems include:
There are many different types of operating system:
The computer network supported by the Computer Science Department at the University of Liverpool runs under a version of UNIX called HP-UX (Hewlett-Packard's own version of UNIX).
To begin using the HP-UX operating system you must first log in. When you login, HP-UX prompts you for your username and password. Your user name identifies you as a valid user of the system. You can not log in if you do not have a user name. Usernames are assigned by the system administrators - the people who manage the department's HP-UX distributed computer system.
A password is an "invisible" codeword known only to its owner and helps to ensure security - it prevents unauthorised users from logging in to your system. Again, you will initially be issued a password by the system administrators. Once you have logged in successfully you will see a command line prompt (e.g. irwell-257 $). As the name suggests a command prompt indicates that the system is ready to accept commands.
To run a command, type the command's name after the command line prompt and press return. To correct typing mistakes use the "back space" key. Commands are simply calls to system programs which run in the same way as any other programs.
One of the first things you should do once you have logged in for the first time is change your password. You do this by running the password command which in turn runs a simple program which guides you through the password changing process. A valid password must:
After you have used your system for a while you will start accumulating a large collection of files. With the help of directories you can organise your files into manageable, logically related groups. For example, if you have several different projects, you can create a directory for each project and store all the files associated with each project in the appropriate directory.
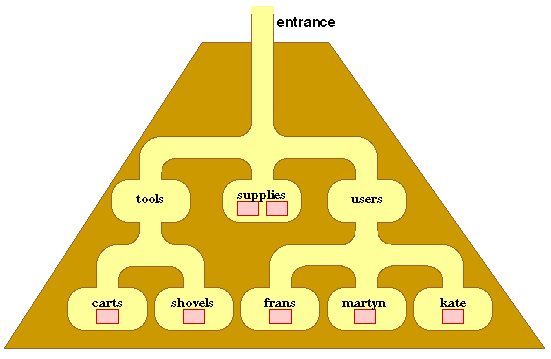
Conceptually directories are like files except that instead of text or data they contain files. Directories are hierarchically organised, i.e. each directory has a parent directory "above" it and may also have child directories "below" it which may in turn have further child directories, and so on. The top most directory is referred to as the root directory. The directories may be likened to chambers in a pyramid:
Comparison between the pyramid conceptualisation and directory structure:
| Chambers | Directories |
|---|---|
| Contain artifacts | Contain files |
| Contains an entrance from above | Has a parent directory |
| May contain passageways to chambers below | May have subordinate child directories |
| Pyramid has one entrance at the top | Directory structure has a root directory at the top |
The directory structure that could be used to represent the rooms and artifacts in the above pyramid is given below (ovals represent directories and boxes files).
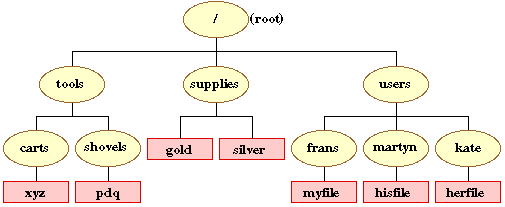
All directories fall under the topmost root directory which is denoted by a slash (/). When using the Unix operating system you are always in a directory - your current directory. When you log in the operating system places you in your home directory. With respect to a distributed computer system your home directory is usually a child of the directory users which is itself a child of the root directory.
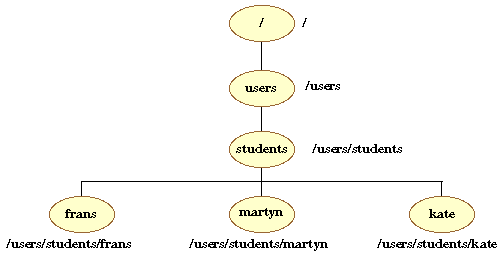
When specifying files in your current directory you can refer to them by their names. However, when referring to files (or directories) outside your current directory you must use path names. A path name specifies where a particular file or directory is located within the directory structure. There are two kinds of path names absolute and relative. Absolute path names specify the path to a file or directory starting from the root directory. The following diagram shows the absolute path names for various files and directories
Relative path names specify directories and files starting from your current directory. The relative path name for your current directory is one dot (.). The relative path name for the parent directory of your current directory is two dots (..). The following diagram shows relative path names for various directories and files starting from the current directory /users/students/frans
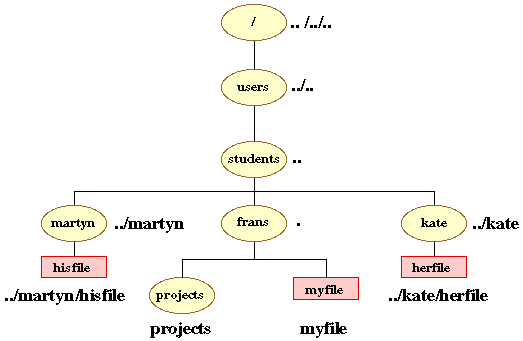
The above illustration shows how one user (once he or she has successfully logged in) can access other users' directories. Clearly most users would not wish this and the HP-UX system supports this. Another user can only access one of your directories if you specifically allow them to (there is a UNIX command to do this). The system administrator, of necessity, has access to all files and directories!
All programming languages are artificial. Each has a limited vocabulary, an explicitly defined grammar, and well-formed rules of syntax and semantics. These attributes are essential for machine translation. We can identify three types of programming language:
We have seen that a program instruction comprises a particular combination of binary digits. Different makes and types of computer use different "codes" of binary digits to represent instructions. Such codes are referred to as machine or instruction codes. In the early days of computer programming all programs had to be written in machine code. For example a short (3 instruction) program might look like this:
0111 0001 0000 1111 1001 1101 1011 0001 1110 0001 0011 1110
Machine code has several disadvantages associated it:
These disadvantages all serve to severely limit the applications to which computers can be applied when using machine code.
Assembler languages were initially developed to address the disadvantages associated with machine code programming. They used symbolic codes instead lists of binary instructions. Consequently programming became more "friendly". An example of assembly code is given below:
MOV AX 01 MOV BX 02 ADD AX BX
In assembler language each line of the program corresponds to one instruction in machine code. For a program written in assembler language to be executable it must be translated into machine code using a translating program called an assembler. Although use of assembly languages offers some advantages there are still a number of significant disadvantages associated with their use:
Note that there are some computer applications, such as interfacing with peripherals, where assembler language is still a necessity
From the early 1950s onwards high level languages were developed with the express aim of providing the means whereby computer programmes could be written more efficiently and in a less error prone manner. The advantages offered are:
Of course programs written in high level languages still have to be translated into machine code instructions if they are to become executable. How this is achieved will be discussed later.
The first high level language to be introduced (c1954) was FORTRAN (FORmula TRANslator) which was originally intended to simplify the writing of programs that made calculations using arithmetic expressions. This was followed in 1959 by COBOL which was designed for programming in the areas of finance and administration. This was followed shortly afterwards, in 1960, by the introduction of ALGOL as a more general purpose language. ALGOL never achieved any great commercial success, however it has significantly influence the subsequent development of many other high level languages including Pascal, C and Ada.
To execute a computer program written in a high level language it must be either compiled or
interpreted. In the case of interpretation each line of the program is decoded and "interpreted" by a
special program
known as an interpreter. Different interpreter are required for different languages (and different
machines). Interpretation occurs every time a line in a program is executed. This means that a line which occurs
many times must be interpreted on each occasion. This wastes computer time, and causes programs to run relatively
slowly. The advantage of interpretation is that interpreters provide a faster and easier way of
testing small programs or fragments of programs. Another,
more questionable advantage, is that parts of a program which are not executed need not be interpreted. In some
cases a text editor and interpreter may be combined into a single programming environment which can be
used to write, edit and interpret a high level language program. The alternative to interpretation is compilation. Here an entire program is first analysed by a special program
called a compiler which converts it into a machine executable form. The advantage is
that the machine executable form runs much faster than if it were interpreted. Again different compilers will be
required for different languages and machines. Created and maintained by
Frans Coenen.
Last updated 11 October 1999
3. COMPILATION VERSUS INTERPRETATION