Ada supports a number of attributes which can be used with respect to array:
where T is an identifier for either a type or a data item. This is unlike other Ada attributes which can only be associated with a type identifier.
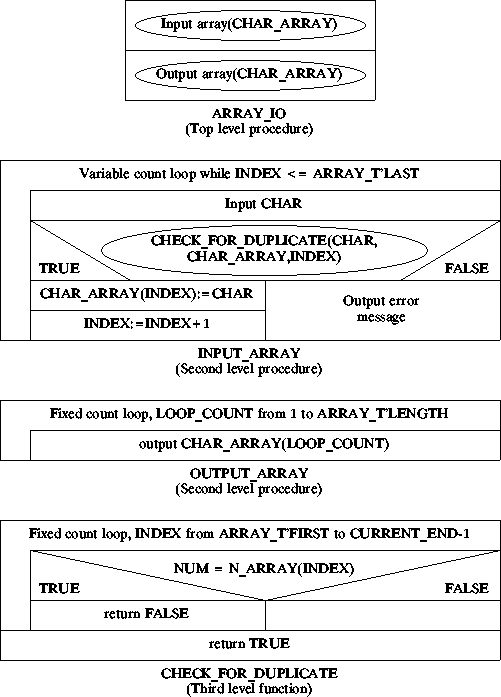
Program to "load" an 8 element character array and the output the result. Program comprises four procedures/functions:
| NAME | USAGE | TYPE | RANGE |
|---|---|---|---|
| CHAR_ARRAY | Global variable | ARRAY_T | Default |
| START_INDEX | Global constant | INTEGER | 1 |
| END_INDEX | Global constant | INTEGER | 8 |
| NAME | USAGE | TYPE | RANGE |
|---|---|---|---|
| CHAR_ARRAY | Formal out parameter | ARRAY_T | Default |
| CHAR | Local input variable | CHARACTER | Default |
| INDEX | Local variable | INTEGER | Default |
| NAME | USAGE | TYPE | RANGE |
|---|---|---|---|
| CHAR_ARRAY | Formal out parameter | ARRAY_T | Default |
| LOOP_COUNT | Local variable | INTEGER | Default |
| NAME | USAGE | TYPE | RANGE |
|---|---|---|---|
| CHAR | Formal parameter | CHARACTER | Default |
| CHAR_ARRAY | Formal out parameter | ARRAY_T | Default |
| CURRENT_END | Formal parameter | INTEGER | Default |
The algorithms involved are described using the Nassi-Shneiderman charts presented below.
The implementation is as follows:
-- ARRAY_IO
-- 3 December 1997
-- Frans Coenen
-- Dept Computer Science, University of Liverpool
with TEXT_IO;
use TEXT_IO;
procedure ARRAY_IO is
START_INDEX : constant := 1;
END_INDEX : constant := 10;
type ARRAY_T is array (START_INDEX..END_INDEX) of CHARACTER;
CHAR_ARRAY : ARRAY_T;
----------------------------------------------------------------------------
-- INPUT ARRAY
procedure INPUT_ARRAY(CHAR_ARRAY : in out ARRAY_T) is
CHAR : CHARACTER;
INDEX : INTEGER := ARRAY_T'FIRST ;
------------------------------------------------------------------------
-- CHECK FOR DUPLICATE
function CHECK_FOR_DUPLICATE(CHAR : CHARACTER; N_ARRAY : ARRAY_T;
CURRENT_END : INTEGER) return BOOLEAN is
begin
for INDEX in ARRAY_T'FIRST..CURRENT_END-1 loop
if CHAR = N_ARRAY(INDEX) then
RETURN(FALSE);
end if;
end loop;
RETURN(TRUE);
end CHECK_FOR_DUPLICATE;
------------------------------------------------------------------------
begin
PUT_LINE("Input character array elements:");
while INDEX <= ARRAY_T'LAST loop
GET(CHAR);
if CHECK_FOR_DUPLICATE(CHAR,CHAR_ARRAY,INDEX) then
CHAR_ARRAY(INDEX):=CHAR;
INDEX:=INDEX+1;
else
PUT("ERROR: Duplicate input ");
PUT(CHAR);
NEW_LINE;
end if;
end loop;
end INPUT_ARRAY;
----------------------------------------------------------------------------
----------------------------------------------------------------------------
-- OUTPUT ARRAY
procedure OUTPUT_ARRAY(CHAR_ARRAY : ARRAY_T) is
begin
for INDEX in START_INDEX..ARRAY_T'LENGTH loop
PUT(CHAR_ARRAY(INDEX));
PUT(" ");
end loop;
NEW_LINE;
end OUTPUT_ARRAY;
----------------------------------------------------------------------------
-- TOP LEVEL
begin
INPUT_ARRAY(CHAR_ARRAY);
OUTPUT_ARRAY(CHAR_ARRAY);
end ARRAY_IO;
Ada supports a number of predefined operations on arrays.
if ARRAY_1 = ARRAY_2 then ... while ARRAY_1 /= ARRAY_2 then ...
ARRAY_1 := ARRAY_2
Ada also supports the concept of slices. A Slice is a sub-array of an array. The process of slicing returns a sub-array. Thus given:
IA: array (INTEGER range N..N+4) of INTEGER := (2,4,6,8,10);
The statement
IA_SUB = IA(N+1..N+3)
would assign the sub array (4,6,8) to IA_SUB (assuming this is declared appropriately).
Arrays can be thought of in terms of lists of elements (as used in declarative languages). As such we can identify a number of common list operations which we may wish to perform:
It is often necessary to carry out a particular operation on all the members of an array. This is called \fImapping, we map the desired operation onto the elements of the array. For example we may wish to cube all the elements of an integer array:
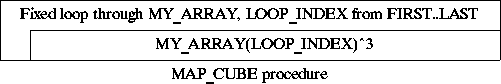
procedure MAP_CUBE(MY_ARRAY: ARRAY_T) is
begin
for LOOP_INDEX in ARRAY_T'FIRST..ARRAY_T'LAST loop
PUT(MY_ARRAY(LOOP_INDEX)**3);
NEW_LINE;
end loop;
end MAP_CUBE;
The process of running through a list and "keeping" only those elements which pass some test is referred to as filtering. For example identifying the odd numbers in an integer array:
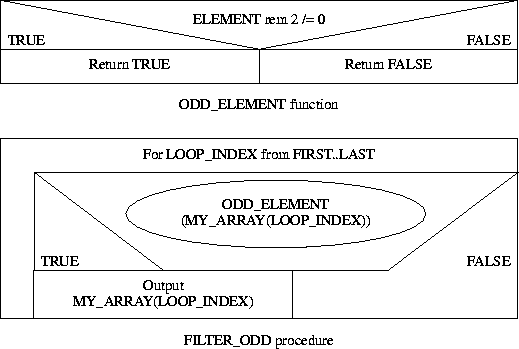
procedure FILTER_ODD(MY_ARRAY: ARRAY_T) is
-------------------------------------------------------------------
-- ODD NUMBER BOOLEAN FUNCTION
function ODD_ELEMENT(ELEMENT: INTEGER) return BOOLEAN is
if (ELEMENT rem 2) /= 0 then
RETURN(TRUE);
else
RETURN(FALSE);
end if;
end ODD_ELEMENT;
------------------------------------------------------------------
begin
for LOOP_INDEX in ARRAY_T'FIRST..ARRAY_T'LAST loop
if ODD_ELEMENT(MY_ARRAY(LOOP_INDEX)) then
PUT(MY_ARRAY(LOOP_INDEX));
NEW_LINE;
end if;
end loop;
end FILTER_ODD;
Note that this assumes an array with elements of type integer.
The process of putting an operator between each pair of elements in an array to produce a single data item is called folding. For example adding up all the elements of a numeric array for the purpose of finding (say) an average value or a total value.

procedure AVERAGE(MY_ARRAY: ARRAY_T) is
TOTAL: FLOAT;
-------------------------------------------------------------------
-- FOLD TOTAL FUNCTION
function FOLD_TOTAL(MY_ARRAY: ARRAY_T) return FLOAT is
FOLD_TOTAL: FLOAT:=0;
begin
for LOOP_INDEX in ARRAY_T'FIRST..ARRAY_T'LAST loop
FOLD_TOTAL := FOLD_TOTAL+MY_ARRAY(LOOP_INDEX)
end loop;
RETURN(FOLD_TOTAL);
end FOLD_TOTAL;
-------------------------------------------------------------------
begin
TOTAL := FOLD_TOTAL(MY_ARRAY);
PUT("Average = ");
PUT(TOTAL/ARRAY_T'LENGTH, EXP=>0);
NEW_LINE;
end AVERAGE;
Note that the above assumes an array with elements of type FLOAT.
The process of combining two arrays to form a third is called zipping. For example we may wish to "inter-leaf" the elements of two arrays.

procedure INTER_LEAF(MY_ARRAY_1, MY_ARRAY_2: in ARRAY_T;
NEW_ARRAY: out ARRAY_BIG_T) is
NEW_INDEX : INTEGER := 1;
begin
for INDEX in ARRAY_T'FIRST..ARRAY_T'LAST loop
NEW_ARRAY(NEW_INDEX) := MY_ARRAY_1(INDEX);
NEW_ARRAY(NEW_INDEX+1) := MY_ARRAY_2(INDEX);
NEW_INDEX := NEW_INDEX+2;
end loop;
end INTER_LEAF;
Note that the new array is returned using the out parameter passing mode.
Develop an Ada program which, given a set of six positive numbers,
determines the intersection
of this set with the set {1, 2, 3, 4, 5, 6}. Note: the input set
should contain no duplicates.
A top-down analysis of the proposed problem is given below.
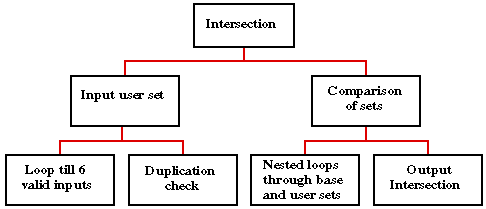
We will represent both the base set and the user defined sets as arrays using a user defined array type SET_T defined as a 6 element array of type INTEGER. We can then identify the following procedures:
| NAME | USAGE | TYPE | RANGE |
|---|---|---|---|
| USER_SET | Local variable (array) | SET | n.a. |
| SET_LENGTH | Local variable | INTEGER | Default |
| SET_ELEMENT | Local variable | INTEGER | Default |
| NAME | USAGE | TYPE | RANGE |
|---|---|---|---|
| USER_SET | Formal parameter (array) | SET | n.a. |
| BASE_SET | Local constant (array) | SET | {1, 2, 3, 4, 5, 6} |
| USER_INDEX | Local variable | INTEGER | Default |
| NAME | USAGE | TYPE | RANGE |
|---|---|---|---|
| USER_SET_SOFAR | Formal parameter (array) | SET | n.a. |
| INPUT_ELEMENT | Formal parameter | INTEGER | Default |
| LENGTH_SOFAR | Formal parameter | INTEGER | Default |
| SET_INDEX | Local variable | INTEGER | Default |
| RETURN_VALUE | Local variable | BOOLEAN | Default |
Complete Nassi-Shneiderman charts for the above are given below:
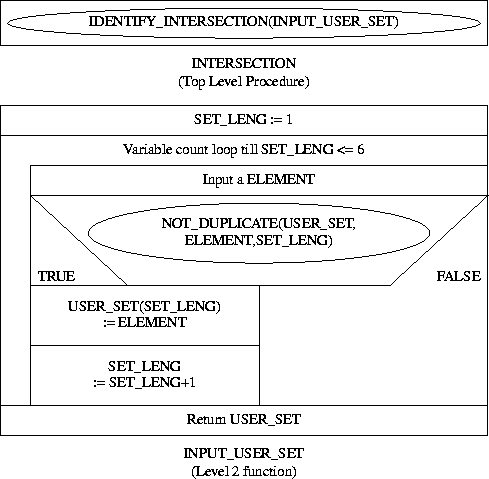
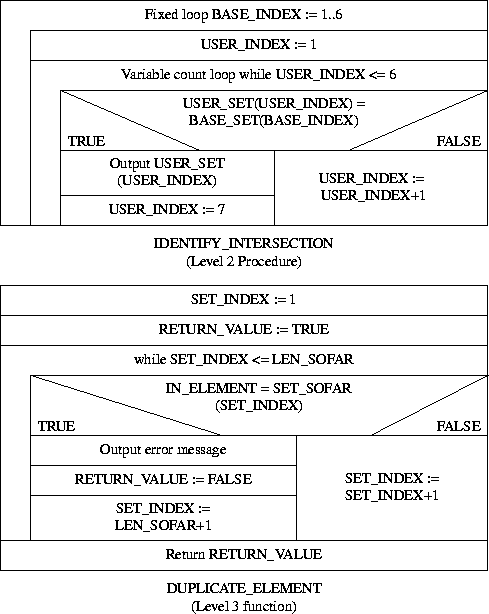
-- INTERSECTION
-- 23 SEPTEMBER 1997
-- Frans Coenen
-- Dept Computer Science, University of Liverpool
with TEXT_IO;
use TEXT_IO;
procedure SET_INTERSECTION is
START_INDEX : constant := 1;
END_INDEX : constant := 6;
package FLOAT_INOUT is new FLOAT_IO(FLOAT);
use FLOAT_INOUT;
package INTEGER_INOUT is new INTEGER_IO(INTEGER);
use INTEGER_INOUT;
type SET_T is array (START_INDEX..END_INDEX) of INTEGER;
-----------------------------------------------------------------------------
-- INPUT_USER_SET
function INPUT_USER_SET return SET_T is
SET_LENGTH : INTEGER := START_INDEX;
SET_ELEMENT : INTEGER;
USER_SET : SET_T := (others => 0);
-------------------------------------------------------------------------
-- NOT_DUPLICATE Boolean function
function NOT_DUPLICATE(USER_SET_SOFAR: SET_T; INPUT_ELEMENT,
LENGTH_SOFAR: INTEGER) return BOOLEAN is
SET_INDEX : INTEGER := 1;
RETURN_VALUE : BOOLEAN := TRUE;
begin
while SET_INDEX <= LENGTH_SOFAR loop
if INPUT_ELEMENT = USER_SET_SOFAR(SET_INDEX) then
PUT("Duplicate input (");
PUT(INPUT_ELEMENT, width=>1);
PUT_LINE(")");
RETURN_VALUE := FALSE;
SET_INDEX := LENGTH_SOFAR+1;
else
SET_INDEX := SET_INDEX+1;
end if;
end loop;
RETURN(RETURN_VALUE);
end NOT_DUPLICATE;
-------------------------------------------------------------------------
begin
PUT("Input a set ");
PUT(END_INDEX-START_INDEX+1,width=>1);
PUT(" (integer) elements: ");
while SET_LENGTH <= END_INDEX loop
GET(SET_ELEMENT);
if NOT_DUPLICATE(USER_SET, SET_ELEMENT, SET_LENGTH-1) then
USER_SET(SET_LENGTH) := SET_ELEMENT;
SET_LENGTH := SET_LENGTH+1;
end if;
end loop;
RETURN(USER_SET);
end INPUT_USER_SET;
-----------------------------------------------------------------------------
-----------------------------------------------------------------------------
-- IDENTIFY_INTERSECTION
procedure IDENTIFY_INTERSECTION(USER_SET : SET_T) is
BASE_SET : constant SET_T := (1, 2, 3, 4, 5, 6);
USER_INDEX : INTEGER := START_INDEX;
begin
PUT("Intersection = { ");
for BASE_INDEX in START_INDEX..END_INDEX loop
USER_INDEX := START_INDEX;
while USER_INDEX <= END_INDEX loop
if USER_SET(USER_INDEX) = BASE_SET(BASE_INDEX) then
PUT(USER_SET(USER_INDEX), width=>1);
PUT(" ");
USER_INDEX := END_INDEX+1;
else
USER_INDEX := USER_INDEX+1;
end if;
end loop;
end loop;
PUT_LINE(" }");
end IDENTIFY_INTERSECTION;
-----------------------------------------------------------------------------
-- INTERSECTION top level procedure
begin
IDENTIFY_INTERSECTION(INPUT_USER_SET);
end SET_INTERSECTION;
BVA, Limit and Arithmetic Testing: Inputs may range from the maximum to the minimum default range for the integer type. We should also include a zero test value. A suitable set of black box test cases is given in the following table.
| TEST CASE | EXPECTED RESULT |
|---|---|
| USER_SET | OUTPUT |
| -2147483649 ... | DATA ERROR |
| 2147483648 ... | DATA ERROR |
| -2147483648 -2147483647 0 2147483646 2147483647 1 | 1 |
Path Testing: We should test each path through the code. More particularly we should test where:
A suitable test USER_SET would then be of the form given below.
| TEST CASE | EXPECTED RESULT |
|---|---|
| USER_SET | OUTPUT |
| 0 2 3 0 1 7 -2 | 2 3 1 |
Note that we replace the duplicate 0 with a 1.
This should also be done.
Example Problem Set Intersection.
Created and maintained by Frans Coenen. Last updated 11 October 1999