|
|
1. INTRODUCTION |
Usually we input values a value at a time following each value by a carriage return. In some cases it is nice to be able to input values as a sequence. We can do this by simply entering the sequence as a string. However, once Java has got the string, to do anything useful with it we must be able to isolate different values within the string. We could do this by painstakingly analysing the string character by character (it is after all a character array) and find the delimiters for each "word" (double quotes are used here as the word in question may in fact be a number or some sequence of special characters). Such words are referred to as tokens. Some example code to achieve this is given in Table 1 together with some output in Table 2. Note that use is made of methods contained in the String class as illustrated previously.
// STRING PROCESSING
// Frans Coenen, Monday 15 January 1999
// Department of Computer Science, The University of Liverpool, UK
import java.io.*;
import java.util.*;
class StringProcessing
{
// Create BufferedReader class instance
static InputStreamReader input = new InputStreamReader(System.in);
static BufferedReader keyboardInput = new BufferedReader(input);
/* Main method */
public static void main(String[] args) throws IOException
{
// Get a string
System.out.println("Input a string ");
String data = keyboardInput.readLine();
// Output number of characters in the line
int numberCharacters = data.length();
System.out.println("Number of characters = " +
numberCharacters + "\n");
// Output tokens
for (int counter=0; counter < numberCharacters; counter++) {
char character = data.charAt(counter);
if (character == ' ') System.out.println();
else System.out.print(character);
}
System.out.println("\n");
}
}
|
Table 1: Processing a string as a character array
$ java StringProcessing Input a string Some sample output resulting from running the above code Number of tokens = 56 Some sample output resulting from running the above code |
Table 2: Sample output generate from string processing code presented in Table 1
2. THE STRING TOKENIZER |
A better way of doing this is to use the StringTokenizer class which is found in the Java package util. This contains a number of useful instance methods which can be used to isolate tokens (Figure 1).
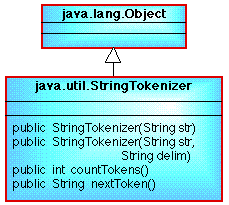
Figure 1: Class diagram showing details of the StringTokenizer class
To use these methods we must of course first create an instance of the class StringTokenizer:
StringTokenizer data = new StringTokenizer(string);where the argument is a string of text. The StringTokenizer class also provides two methods which are immediately useful for processing strings:
In the following piece of code (Table 3) we use these methods to identify and output the tokens in a string provided by the user.
// TOKENIZER EXAMPLE
// Frans Coenen, Monday 15 January 1999
// Department of Computer Science, The University of Liverpool, UK
import java.io.*;
import java.util.*;
class TokenizerExample
{
// Create BufferedReader class instance
static InputStreamReader input = new InputStreamReader(System.in);
static BufferedReader keyboardInput = new BufferedReader(input);
/* Main method */
public static void main(String[] args) throws IOException
{
int numberOfTokens=0;
// Get a string
System.out.println("Input a string ");
StringTokenizer data = new StringTokenizer(keyboardInput.readLine());
// Output number of tokens in the line
numberOfTokens = data.countTokens();
System.out.println("Number of tokens = " + numberOfTokens + "\n");
// Output tokens
for (int counter=0; counter < numberOfTokens; counter++) {
System.out.println(data.nextToken());
}
}
}
|
Table 3: Tokenizing example
Some sample output resulting from running the above code is given in Table 4.
$ java TokenizerExample Input a string Some sample output resulting from running the above code Number of tokens = 9 Some sample output resulting from running the above code |
Table 4: Sample output generate from tokenizing code presented in Table 3
3. USING THE STRING TOKENIZER TO PROCESS A SEQUENCE OF NUMBERS |
The java code presented in Table 5 processes a sequence of comma separated integers using the methods found in the StringTokenizer class. Note that, by default the delimiter is a white space character, in this case we have specified the nature of the delimiter, i.e. a comma, as part of the constructor. Note that, whatever the delimiter is defined as, it is not considered to be a token in its own right. Note also that we use the integer wrapper class methods (as illustrated previously) to convert the individual tokens from strings to integers. In Table 6 some sample output is presented.
// TOKENIZER EXAMPLE 2
// Frans Coenen, Tuesday 18 January 2000
// Department of Computer Science, The University of Liverpool, UK
import java.io.*;
import java.util.*;
class TokenizerExample2 {
// Create BufferedReader class instance
static InputStreamReader input = new InputStreamReader(System.in);
static BufferedReader keyboardInput = new BufferedReader(input);
/* Main method */
public static void main(String[] args) throws IOException
{
int numberOfTokens=0;
int numberArray[];
int total=0;
// Get a string
System.out.print("Input a sequence of integers separated by " +
"commas (`,'): ");
StringTokenizer data = new
StringTokenizer(keyboardInput.readLine(),",");
// Get number of tokens in line and initialise array
numberOfTokens = data.countTokens();
System.out.println("Number of tokens = " + numberOfTokens + "\n");
numberArray = new int[numberOfTokens];
// Isolate tokens and maintain total
for (int counter=0; counter &ly numberOfTokens; counter++) {
numberArray[counter] = new Integer(data.nextToken()).intValue();
System.out.println(numberArray[counter]);
total = total+numberArray[counter];
}
// Output total
System.out.println("------------\n" + total + " (average = " +
total/numberOfTokens + ")");
}
}
|
Table 5: Tokenizing example
$ java TokenizerExample2 Input a sequence of integers separated by commas (`,'): 1,2,3,4,5,6,7 Number of tokens = 7 1 2 3 4 5 6 7 ------------ 28 (average = 4) |
Table 6: Sample output generate from tokenizing code presented in Table 3
4. USING MORE THAN ONE DELIMETER |
Sometimes we wish to tokenize using several delimeters. For example we might wish to process a text file which contains markup tags enclosed in pairs of [% and %]. For Example:
Welcome to [%name%] page. Today is [%date%], and it is [%time%]. Today's picture is [%picture%] Today's quote is [%quote%>]
We could define a tokenizer as follows:
StringTokenizer openTagTokenizer = new StringTokenizer(keyboardInput.readLine(),"[%");
This might allow us to identify all the sub-strings separated by [%, and then we could process these substrings using a second tokenizer. The two tokenizer idea is a good one, but the tokenizer as defined above will not quite work as expected. The delimeter [%. is interpreted as either [% or [ or %. Thus the string:
Welcome to [%name%] page.
would be considered to comprise three sub-strings: Welcome to, name and ]page. (and not two --- Welcome to and name %] page. --- as might have been anticupated). Thus to identify our tags we should first look for [ and then test the first element of the resulting sub-string for %, if found we have the start of a tag which can then be processed by the second tokenizer. The code presented in Table 7 can be used to identify tags in text in this manner.
// TOKENIZER EXAMPLE 8
// Frans Coenen, Friday 28 June 2002
// Department of Computer Science, The University of Liverpool, UK
import java.io.*;
import java.util.*;
class TokenizerExample8 {
// Create BufferedReader class instance
static InputStreamReader input = new InputStreamReader(System.in);
static BufferedReader keyboardInput = new BufferedReader(input);
/* Main method */
public static void main(String[] args) throws IOException {
// Define "startTag" tokenizer and get a string
System.out.print("Input some text containing markup tags delimited " +
"by \"[%\" and \"%]\", for example \"The [%DATE%] is\" = ");
StringTokenizer openTagTokenizer = new
StringTokenizer(keyboardInput.readLine(),"[");
// Get number of tokens in line
int numberOfTokens = openTagTokenizer.countTokens();
System.out.println("Number of tokens = " + numberOfTokens);
// Define variable to hold substring
String subString;
for (int counter=0; counter < numberOfTokens; counter++) {
subString = openTagTokenizer.nextToken();
// If substring starts with '%' we have a tag, otherwise ignore
if (subString.charAt(0) == '%') findTag(subString);
}
}
/* FIND TAG */
private static void findTag(String str) {
// Define string tokenizert with "%]" delimeter
StringTokenizer closeTagTokenizer = new StringTokenizer(str,"%");
// Output
System.out.println("TAG = " + closeTagTokenizer.nextToken());
}
}
|
Table 7: String tokenizing with several delimeters
Some sample output is presented in Table 8. Note that the input string should be all on one line with a "carriage return" at the end.
$ java TokenizerExample8 Input some text containing markup tags delimited by "[%" and "%]", for example "The [%DATE%] is" = Welcome to [%name%] page. Today is [%date%], and it is [%time%]. Today's picture is [%picture%] Today's quote is [%quote%>] Number of tokens = 6 TAG = name TAG = date TAG = time TAG = picture TAG = quote |
Table 8: Sample output produced by code presented in Table 7
5. STRING TOKENIZING AND FILE HANDLING |
We can also use the string tokenizer to process input from a file line by line as shown in Table 9. Here we read a file called HelloWorld2 in the same manner as illustrated previously and then use the tokenizer to identify and output the contents.
// STRING TOKENIZER EXAMPLE TO READ A FILE
// Frans Coenen, Saturday 22 January 1999
// Department of Computer Science, The University of Liverpool, UK
import java.io.*;
import java.util.*;
class TokenizerExample3 {
/* Main method */
public static void main(String[] args) throws IOException {
FileReader file = new FileReader("HelloWorld2.java");
BufferedReader fileInput = new BufferedReader(file);
final int NUMBER_OF_LINES_IN_FILE = 31;
int numberOfTokens = 0;
// Read file
for(int counter=0;counter < NUMBER_OF_LINES_IN_FILE;counter++) {
StringTokenizer dataLine =
new StringTokenizer(fileInput.readLine());
numberOfTokens = numberOfTokens + dataLine.countTokens();
}
// Output result and close file
System.out.println("Number of tokens = " + numberOfTokens);
fileInput.close();
}
}
|
Table 9: Using the string tokenizer to process a text file (example 1)
From the code presented above we can see that we use knowledge of the size (NUMBER_OF_LINES_IN_FILE) of the input file to control the "input" loop in the same way that we did in the previous work on file handling. If we knew that the input file did not contain any blank lines, one way of avoiding the need to know in advance the number of lines in the input file, is to process the file until a line with no tokens is found and assume that this is the end of the file. Some appropriate code to achieve this is given in Table 10.
public static void main(String[] args) throws IOException {
FileReader file = new FileReader("HelloWorld2.java");
BufferedReader fileInput = new BufferedReader(file);
int totalNumOfTokens = 0, numberOfTokens = 0;
// Read file
StringTokenizer dataLine = new StringTokenizer(fileInput.readLine());
numberOfTokens = dataLine.countTokens();
while (numberOfTokens != 0) {
totalNumOfTokens = totalNumOfTokens + numberOfTokens;
dataLine = new StringTokenizer(fileInput.readLine());
numberOfTokens = dataLine.countTokens();
}
// Output result and close file
System.out.println("Number of tokens = " + totalNumOfTokens);
fileInput.close();
}
|
Table 10: Using the string tokenizer to process a text file (example 2)
The format of code is useful if we wish to read a file line by line and process each line in turn. Table 11 shows the contents of a file containing numeric data. If we wish to read this file line by line and identify the individual integers in each line we can use the string tokenizer approach described above. Note that the data file is completed with a blank line which we can use to single the end of file (EOF). The code is presented in Table 12.
24 53 46 78 92 3 56 8 90 12 56 12 5 78 4 2 61 87 82 97 91 41 88 91 59 92 83 94 12 91 65 87 68 68 82 2 8 38 94 34 80 91 85 18 17 13 69 90 47 66 32 47 9 65 54 59 18 21 97 63 29 43 12 26 6 49 84 89 29 25 71 16 17 77 55 24 19 98 8 13 92 1 96 73 75 27 87 53 52 39 80 81 25 81 13 72 0 73 53 33 85 94 55 98 3 89 12 53 8 51 2 3 48 58 65 67 52 53 93 89 52 89 50 |
Table 11: Sample numeric data
// Stream TOKENIZER EXAMPLE --- Reading a sequence of numbers
// Frans Coenen, Saturday 22 January 1999
// Department of Computer Science, The University of Liverpool, UK
import java.io.*;
import java.util.*;
class TokenizerExample7 {
/* Main method */
public static void main(String[] args) throws IOException {
FileReader file = new FileReader("numeric.data");
BufferedReader fileInput = new BufferedReader(file);
int counter, numberOfTokens = 0, number;
// Read file
StringTokenizer dataLine =
new StringTokenizer(fileInput.readLine());
numberOfTokens = dataLine.countTokens();
while (numberOfTokens != 0) {
for (counter=0; counter < numberOfTokens; counter++) {
number = new Integer(dataLine.nextToken()).intValue();
number++;
System.out.print(number + " ");
}
System.out.println();
dataLine = new StringTokenizer(fileInput.readLine());
numberOfTokens = dataLine.countTokens();
}
}
}
|
Table 12: Reading a file using the string tokenizer.
The final output will be as shown in Table 13.
$ java TokenizerExample7 25 54 47 79 93 4 57 9 91 13 57 13 6 79 5 3 62 88 83 98 92 42 89 92 60 93 84 95 13 92 66 88 69 69 83 3 9 39 95 35 81 92 86 19 18 14 70 91 48 67 33 48 10 66 55 60 19 22 98 64 30 44 13 27 7 50 85 90 30 26 72 17 18 78 56 25 20 99 9 14 93 2 97 74 76 28 88 54 53 40 81 82 26 82 14 73 1 74 54 34 86 95 56 99 4 90 13 54 9 52 3 4 49 59 66 68 53 54 94 90 53 90 51 |
Table 13: Output from code presented in Table 10.
The code in Table 14 is used to process two files of equal length (number of lines) and "zip" the two together by inter-leaving the lines from the two files into a third output file. The output file is consequently twice the length of any one of the two input files.
// FILE INTERLEAVE EXAMPLE
// Frans Coenen, Monday 18 December 2000
// Department of Computer Science, The University of Liverpool, UK
import java.io.*;
import java.util.*;
class FileInterleave {
// Create FileWriter and PrintWriter class instances
/* Main method */
public static void main(String[] args) throws IOException
{
BufferedReader inputFile1 = new
BufferedReader(new FileReader("inputFile1"));
BufferedReader inputFile2 = new
BufferedReader(new FileReader("inputFile2"));
PrintWriter outputFile = new
PrintWriter(new FileWriter("outputFile"));
String lineFromFile1;
int numberOfTokens = 0;
// Read file
lineFromFile1 = inputFile1.readLine();
StringTokenizer dataLine = new StringTokenizer(lineFromFile1);
numberOfTokens = dataLine.countTokens();
while (numberOfTokens != 0) {
// Output line from file 1
outputFile.println(lineFromFile1);
// Output line from file 2
outputFile.println(inputFile2.readLine());
// Read next line from file 2
lineFromFile1 = inputFile1.readLine();
dataLine = new StringTokenizer(lineFromFile1);
numberOfTokens = dataLine.countTokens();
}
// Close file
inputFile1.close();
inputFile2.close();
outputFile.close();
}
}
|
Table 14: File interleave utility
The code in Table 15 is used to output the first N lines of a file to another file. Note that the file name and the value of N are presented as command line arguments. Note also that the code includes the checkFile method introduced previously.
// FILE OUTPUT EXAMPLE (OUTPUT FIRST N LINES)
// Frans Coenen
// Tuesday 30 January 2001
// Department of Computer Science, The University of Liverpool, UK
import java.io.*;
import java.util.*;
class FileOutputExample {
/* Main method */
public static void main(String[] args) throws IOException {
// Get file name and number of lines to output (counter)
int counter = Integer.parseInt(args[1]);
String fileName = new String(args[0]);
// CheckFile
if (!checkFile(fileName)) System.exit(1);
// Prepare input and output files
BufferedReader inputFile = new
BufferedReader(new FileReader(fileName));
PrintWriter outputFile = new
PrintWriter(new FileWriter("outputFile"));
String lineFromFile;
int numberOfTokens = 0;
// Read file
lineFromFile = inputFile.readLine();
StringTokenizer dataLine = new StringTokenizer(lineFromFile);
numberOfTokens = dataLine.countTokens();
for (int index = 0;index < counter;index++) {
if (numberOfTokens == 0) break;
// Output
outputFile.println(lineFromFile);
// Read next line from file
lineFromFile = inputFile.readLine();
dataLine = new StringTokenizer(lineFromFile);
numberOfTokens = dataLine.countTokens();
}
// Close file
inputFile.close();
outputFile.close();
}
/* Check File */
private static boolean checkFile(String fileName) {
File src = new File(fileName);
if (src.exists()) {
if (src.canRead()) {
if (src.isFile()) return(true);
else System.out.println("ERROR 3: File is a directory");
}
else System.out.println("ERROR 2: Access denied");
}
else System.out.println("ERROR 1: No such file");
return(false);
}
}
|
Table 15: Java application class to output first "N" liner of an input file to an output file
The code in Table 16 is used to process two files of the form:
File 1 |
File 2 |
i.e. of equal length (number of lines); and merge the contents by combing pairs of lines from the files into a third output file. Thus given the above tow files this will produce:
1 2 3 4 1 2 3 4 5 6 1 2 3 4 5 6 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 |
File 3
// FILE MERGE EXAMPLE
// Frans Coenen, Tuesday 30 January 2000
// Department of Computer Science, The University of Liverpool, UK
import java.io.*;
import java.util.*;
class FileMergeExample {
/* Main method */
public static void main(String[] args) throws IOException {
String lineFromFile1, lineFromFile2;
int numberOfTokens1 = 0, numberOfTokens2;
// Get file names
String fileName1 = new String(args[0]);
String fileName2 = new String(args[1]);
// CheckFile
if (!checkFile(fileName1)) System.exit(1);
if (!checkFile(fileName2)) System.exit(1);
// Create FileWriter and PrintWriter class instances
BufferedReader inputFile1 = new
BufferedReader(new FileReader(fileName1));
BufferedReader inputFile2 = new
BufferedReader(new FileReader(fileName2));
// Read file
lineFromFile1 = inputFile1.readLine();
lineFromFile2 = inputFile2.readLine();
StringTokenizer dataLine1 = new StringTokenizer(lineFromFile1);
StringTokenizer dataLine2 = new StringTokenizer(lineFromFile2);
numberOfTokens1 = dataLine1.countTokens();
numberOfTokens2 = dataLine2.countTokens();
while (numberOfTokens1 != 0) {
mergeLine(dataLine1,dataLine2,numberOfTokens1,numberOfTokens2);
// Read next lines
lineFromFile1 = inputFile1.readLine();
lineFromFile2 = inputFile2.readLine();
dataLine1 = new StringTokenizer(lineFromFile1);
dataLine2 = new StringTokenizer(lineFromFile2);
numberOfTokens1 = dataLine1.countTokens();
numberOfTokens2 = dataLine2.countTokens();
}
System.out.println("\n");
// Close file
inputFile1.close();
inputFile2.close();
}
/* MERGE LINE */
public static void mergeLine(StringTokenizer dl1, StringTokenizer dl2,
int length1, int length2) {
int n1 = new Integer(dl1.nextToken()).intValue();
int n2 = new Integer(dl2.nextToken()).intValue();
while(true) {
// Both same
if (n1 == n2) {
System.out.print(n1 + " ");
length1--;
length2--;
if (!checkForNext(dl1,dl2,length1,length2,0,0)) break;
n1 = new Integer(dl1.nextToken()).intValue();
n2 = new Integer(dl2.nextToken()).intValue();
}
else {
// First less than second
if (n1 < n2) {
System.out.print(n1 + " ");
length1--;
if (!checkForNext(dl1,dl2,length1,length2,2,n2)) break;
n1 = new Integer(dl1.nextToken()).intValue();
}
// Second less than first (by default)
else {
System.out.print(n2 + " ");
length2--;
if (!checkForNext(dl1,dl2,length1,length2,1,n1)) break;
n2 = new Integer(dl2.nextToken()).intValue();
}
}
}
}
/* CHECK FOR NEXT: Flag settings:
0 = Nothing
1 = Output number before rest of dataline1
2 = Output number before rest of dataline2 */
public static boolean checkForNext(StringTokenizer dl1,
StringTokenizer dl2, int length1, int length2,
int flag, int oldNumber) {
int index, number;
// Check first data line
if (length1 == 0) {
// Output second data line if not empty
if (length2 != 0) {
if (flag == 2) {
System.out.print(oldNumber + " ");
length2--;
}
outputRest(dl2,length2);
}
// Both empty
else System.out.println();
return(false);
}
// Check second data line
if (length2 == 0 && flag != 2) {
// Output first data line (which we know not to be empty)
if (flag == 1) {
System.out.print(oldNumber + " ");
length1--;
}
outputRest(dl1,length1);
return(false);
}
// Otherwise both OK
return(true);
}
/* OUTPUT REST */
private static void outputRest(StringTokenizer dataLine, int length) {
int number;
for(int index=0;index < length;index++) {
number = new Integer(dataLine.nextToken()).intValue();
System.out.print(number + " ");
}
System.out.println();
}
/* CHECK FILE */
private static boolean checkFile(String fileName) {
File src = new File(fileName);
if (src.exists()) {
if (src.canRead()) {
if (src.isFile()) return(true);
else System.out.println("ERROR 3: File is a directory");
}
else System.out.println("ERROR 2: Access denied");
}
else System.out.println("ERROR 1: No such file");
return(false);
}
}
|
Table 16: File merge utility
Created and maintained by Frans Coenen. Last updated 21 May 2003