|
|
|
1. VARIABLES AND CONSTANTS |
|
Given that we can always replace a particular bit pattern with another, the value of a data item can always be changed. Data items that are intended to be used in this way are referred to as variables. We sometimes refer to instance/class variables. The value associated with a variable can be changed using what is called an assignment operation. In the case of Java this is indicated by the symbol `=` as illustrated previously. In Jave, by default (as is the case with many programming languages), data items are assumed to be variables. All the integer data items declared in the DataInitialisation class definition presented eralier are interpreted in this way. (The DataInitialisation instance, although also a data item, is interpreted in a different way because it is a reference to a compound data item, but more on this later.) |
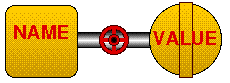
Figure 1: Constant data item (click on components!). However it should be appreciated that what we are doing here is telling the compiler to "flag" the data item as a constant (i.e. we are only instigating software protection). Theoretically we can still change the bit pattern representing the value if we can ascertain its address, i.e. find where it is stored. The use of named or symbolic constants offers three advantages: |
|
It is sometimes desirable to define a data item whose value cannot be changed. Such data items are referred to as constants. In Java constants are defined by incorporating the key word final into the declaration (to indicate that they already have their "final" value!): final int CONSTANT_DATA_ITEM = 2; Here we have declared a constant CONSTANT_DATA_ITEM which has a value of 2. Note that by convention constant identifiers are always encoded using upper-case letters --- this allows for their easy identification, makes the code more readable and consequently more maintainable. Conceptually we can think of a constant as a data item comprising only a name and a value (i.e. no address) as shown in Figure 1. |
Named constants therefore enhance the maintainability of a program. Note also that fields defined within a class may also be variables or constants. We sometimes refer to instance variables/constants or class variables/constants. |
2. ANONYMOUS DATA ITEMS |
|
Often we use data items in a program without giving them a name, such data items are referred to as anonymous data items. For example in the assignment expression: dataItem1 = 2 + (5*6); The (5*6) part of the expression is calculated first and the result (30) stored as a data item with an address etc., but without a label (Figure 2). |

Figure 2: Anonymous data item The significance is that anonymous data items cannot be changed or used again in other parts of a program. We can think of an anonymous data item as a data item without a name, as such we cannot access its address (and hence the value stored at this address). |
3. UNINITIALISED VARIABLES |
|
In some language it is possible to define uninitialised data items, i.e. an uninitialised variable. Of course the binary digits at the indicated address will have some setting (left over from previous executions of programs) and therefore the data item will have some arbitrary value associated with it. The presence of such data items can result in errors. We can conceive of an uninitialised data item as shown in Figure 3. |

Figure 3: Uninitialised data item In Java uninitialised data items are automatically assigned a value. In the case of numeric data items the default initialisation is 0. |
4. OBJECT REFERENCES |

Figure 4: Object reference data item
|
An instance of a class is a data item the same as any other (all be it an extremely complex one). When we create an instance a section of memory is set aside (on the heap) for this item. When we create an instance of a class this is the same as creating any other data item except that the immediate value associated with the data item name is an address rather than a value. This address indicates the start of the section of memory reserved in the heap for the object (Figure 4). This is because an object is what we call a compound data item in that it can have more than one value associated with it at the same time, and therefore needs a sequence of memory slots (one for each value). The immediate value associated with an instance name is thus the address of the start of this block of memory. We refer to such address values as object references (because they "reference" the start address in the heap for the values associated with the indicated compound data item). In some languages (e.g. C and C++) such data items are called pointers in that they "point" to the start of a section of memory in the heap. For example if we create an instance, newInst1, of the class ExampleClass: |
ExampleClass newInst1 = new ExampleClass(); This will create a data item of the form shown in Figure 5. The data item like any other data item has an address, 100000 in the example (which is also stored on the heap), and a value (102000) which is a reference value that points to another section of the heap where the instance fields for newInst1 are stored. 
Figure 5: The data item newInst1 |
|
In an earlier example we used a constructor to create an instance of the class GrandParent as follows: Grandparent mary = new GrandParent(); Here we have created the object mary which is an instance of the class GrandParent and which has been initialised with a reference value indicating the storage location of all the associated data items. |
It is possible to create an object such as mary and leave the initialisation till later. We do this using a "data declaration" of the form: Grandparent mary = null; the null indicates a special value, contained in the java.util package, of "nothing" (not zero but nothing!), i.e. the reference value does not point to anything. |
|
We can have two or more names which identify the same object. For example, given the object newInst1 created above we can "assign" its immediate value (which remember is an object reference, i.e. an address) to another label as follows: |
newInst2 = newInst1; with a result as depicted in Figure 6. This is called aliasing and should be avoided as it causes confusion --- we have not made a copy of the object but created a second means of accessing it! (see Figure 6). |

Figure 6: Aliasing
5. DATA TYPES |
|
We have seen that the type of a data item defines:
We have seen that the process of associating a type with a data item is referred to as a data declaration. This binds a data item name to a type definition. The process of assigning a value to a data item on declaration of that item is referred to as initialisation. (This was illustrated in the data initialisation example program presented earlier.) |
Java supports eight primitive (basic) data types as summarised in Table 1. The significance of the Unicode 2.0 value associated with the char data type will be expanded upon later. The purpose of the boolean type will also be expanded upon later in the text. All the above have specific storage and interpretation considerations associated with them and both have particular operations which may be applied to them. For example the numeric types have the + and - arithmetic operations associated with them. Note that these operations are overloaded, there is one plus operation for integer addition and one for real number addition. To mix (say) integer and real number addition - so called mixed mode arithmetic - requires special consideration (again more of this later). |
| Type | Identifier | Bits | Values |
|---|---|---|---|
| Character | char | 16 | Unicode 2.0 |
| 8-bit signed integer | byte | 8 | -128 to 127 |
| Short signed integer | short | 16 (2 bytes) | -32768 to 32767 |
| Signed integer | int | 32 (4 bytes) | -2,147,483,648 to +2,147,483,647 |
| Signed long integer | long | 64 (8 bytes) | maximum of over 1018 |
| Real number (single precision) | float | 32 (4 bytes) | Maximum of over 1038 (IEEE 754-1985) |
| Real number (double precision) | double | 64 (8 bytes) | Maximum of over 10308 (IEEE 754-1985) |
| Boolean | boolean | true or false |
Table 1: Java basic data types
6. CATEGORISATION OF TYPES |
7. EXAMPLE PROBLEM --- GIANT JAVA7.1. RequirementsTo write the word "Java" vertically down the screen using giant letters made up of strings of * (asterisk) characters and blank spaces as shown in Figure 7. 
Figure 7: Giant letters 7.2. System Analysis
7.3. Design7.3.1. GiantJava Class
The design detail required for each of the GiantJava class methods is given by the Nassi-Shneiderman charts presented in Figure 10. 
Figure 10: Nassi-Shneiderman chart for GiantJava class methods 7.3.2. GiantJavaApp Class
A Nassi-Shneiderman chart for the main method is given in Figure 11. Note how method invocation (referred to as routine invocation in imperative languages) is indicated in the chart using the routine name surrounded by an ellipse. Note also that the "Draw giant letter A" operation is repeated twice.
Table 3: Giant letters application class
| |||||||||||||||||||||||||||
8. PROGRAM DOCUMENTATION |
|
There is more to producing a computer solution to a problem then simply producing a well engineered piece of software that meets the requirements specification. Both the software development process and the software itself should be supported by appropriate documentation. This offers several advantages:
|
To adhere to the above all solutions to COMP101 practical problems should be presented in the form of a "document" comprising:
|
Created and maintained by Frans Coenen. Last updated 10 February 2015


