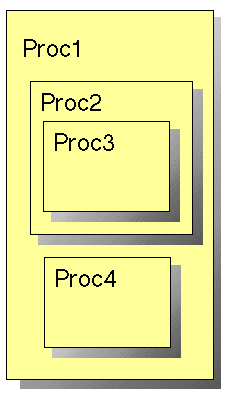
These will be discussed later. It should also be noted that although the concepts remain the same routines or
subprograns are referred to by different names in different languages. In C routines are referred to as
functions. In Pascal and Ada they are called procedures and functions. Modula-2 names them
procedures (even if some of them are actually functions). COBOL uses the terms paragraphs, while
FORTRAN and BASIC refer to them as sub-routines and
functions.
2.1. FORMAL PARAMETERS
- The arguments for a routine (if any) are referred to as its formal parameters.
- The values which are to be assigned to these formal parameters are referred to as the
actual parameters.
- Actual parameters can be variables, constants or expressions.
- Names chosen for actual parameters are completely independent of those chosen for the
formal parameters.
- Most imperative languages (Ada and C included) use positional parameters, this means that
any actual parameters supplied must agree with the formal parameters in number, order and type.
- Alternatives include keyword or default parameters (both are
supported by Ada), but more on this later.
2.2. PROCEDURES AND FUNCTIONS
We can identify two types of routine:
- Procedures.
- Functions.
The distinction between a procedure and a function is that a function returns a value while
a procedure does not. A function declaration must therefore be called
as part of an assignment expression and incorporate a definition for its return value.
Some imperative languages (Ada, FORTRAN, Pascal) make a clear distinction between procedures and functions.
Other imperative languages (C, ALGOL 68) do not.
A procedure (function) comprises a head and a body. In the head the name of the
routine and its are specified. In the body the necessary
code is given.
Functions and procedures are
activated by a procedure or function
call which names the routine and supplies the actual parameters.
Most imperative languages (Ada and C included) use positional parameters. Examples:
AVERAGE:= MEAN_VALUE(4.2, 9.6); (Ada)
average = meanValue(4.2, 9.6); (C)
Alternatives include keyword or default parameters.
2.3. ADA AND C EXAMPLE PROCEDURES AND FUNCTIONS
Ada Procedure Example:
with CS_IO ; use CS_IO ;
procedure PROC_EXAMPLE is
NUM_X, NUM_Y: float;
procedure MEAN_VALUE (VALUE_1, VALUE_2: float) is
begin
put("MEAN VALUE PROCEDURE");
new_line;
put("====================");
new_line;
put("The mean is ");
put((VALUE_1+VALUE_2)/2.0);
new_line;
end MEAN_VALUE;
begin
get(NUM_X); get(NUM_Y);
MEAN_VALUE(NUM_X,NUM_Y);
end PROC_EXAMPLE;
|
Ada Function Example:
with CS_IO ; use CS_IO ;
procedure FUNC_EXAMPLE is
NUM_X, NUM_Y, NUM_Z: float;
function MEAN_VALUE (VALUE_1, VALUE_2: float) return float is
begin
put("MEAN VALUE FUNCTION");
new_line;
put("====================");
new_line;
return (VALUE_1+VALUE_2)/2.0;
end MEAN_VALUE;
begin
get(NUM_X);
get(NUM_Y);
Z:= MEAN_VALUE(NUM_X,NUM_Y);
put("The mean is ");
put((NUM_X+NUM_Y)/2.0);
new_line;
put("The mean is ");
put(Z);
new_line;
end FUNC_EXAMPLE;
|
C Procedure Example:
#include <stdio.h>
void meanValue(float, float);
void main(void)
{
float num_x, num_y;
scanf("%f%f",&num_x,&num_y);
meanValue(num_x,num_y);
}
void meanValue(float value1, float value2)
{
printf("MEAN VALUE PROCEDURE\n");
printf("====================\n");
printf("\nThe mean is %f\n",(value1+value2)/2.0);
}
|
C Function Example:
#include <stdio.h>
float meanValue(float, float);
void main(void)
{
float num_x, num_y;
printf("Enter 2 real numbers ");
scanf("%f%f",&num_x,&num_y);
printf("MEAN VALUE FUNCTION\n");
printf("===================\n");
printf("\nThe mean is %f\n",meanValue(num_x,num_y));
}
float meanValue(float value1, float value2)
{
return((value1+value2)/2.0);
}
|
2.4. ORDER OF PROCEDURE DECLARATIONS IN BLOCK STRUCTURED LANGUAGES
In block structured languages the order in which procedures are declared also
effects visibility. Ada (and other block structured languages such as Pascal)
requires that any use of an identifier must be preceded
by its declaration. Thus if two procedures are declared at the same level, their
order of declaration will dictate "who can call whom". The procedure currently
being declared cannot see any following procedures. In Ada this
can be overcome by using an incomplete declaration. Ordering of procedure
declarations is not significant in C.
Note also that in languages such as Ada and Pascal a following procedure cannot
see a procedure or function nested within a previous procedure or
function. Consider the following piece of code (nesting given to right):

with CS_IO;
use CS_IO;
procedure SUM_AND_PROD is
X_ITEM : constant := 2;
Y_ITEM : constant := X_ITEM*2;
--------------------------------------------------
procedure SUM(P_ITEM, Q_ITEM : INTEGER) is
TOTAL : INTEGER ;
------------------------------------------------
procedure SUMMATION(R_ITEM, S_ITEM : INTEGER) is
begin
TOTAL := R_ITEM + S_ITEM;
PUT(TOTAL);
NEW_LINE;
end SUMMATION;
------------------------------------------------
begin
SUMMATION(P_ITEM, Q_ITEM);
end SUM;
--------------------------------------------------
procedure PRODUCT(P_ITEM, Q_ITEM : INTEGER) is
begin
PUT(P_ITEM * Q_ITEM);
NEW_LINE;
SUM(P_ITEM, Q_ITEM);
end PRODUCT;
--------------------------------------------------
begin
PRODUCT(X_ITEM,Y_ITEM);
end SUM_AND_PROD;
|
Here the procedure PRODUCT can see the procedure SUM because it is at the same level and
declared before it. The procedure PRODUCT cannot see SUMMATION because it is nested within the
procedure SUM. Conversely the procedure SUM cannot see the procedure PRODUCT because it
is declared after it (despite being at the same level), however it can see the procedure SUMMATION
because it is nested within it.
3. SCOPE RULES
Scope rules govern the visibility of data items (i.e. the parts of a program where they can be
used). They also bind names to types.
Where this is determined at compile time this is called static scoping. The opposite is dynamic scoping. Dynamic scoping is generally a feature
of logic languages such as PROLOG and functional languages such as LISP.
The advantages of static scoping is that it allows type checking to be carried out at compile time.
Most imperative languages use static scoping.
Generally speaking, in
imperative languages, the scope of a declaration commences at the end of the declaration statement and continues
to the end of the block.
3.1. ADA SCOPE RULES
- Scope of declaration extends from where it is made to the end of the block
in which the declaration is made.
- Anything declared in a block is not visible outside of that block.
- Anything declared in a block is however visible to all enclosed blocks
within it in which the data item is not redeclared.
- Several items with the same name cannot be used in the same
block, however several items with the same name can be declared in "different" blocks. In this case the declared quantities
have nothing to do with one another (other than sharing the same name).
- Where a name is used in a block and reused in a sub-block nested within it, the sub-block declaration
will override the super-block declaration during the life time of the sub-block.
This is referred to as
occlusion. The identifier which is hidden because of the inner
declaration is said to be occluded.
[A]
A data item is visible from where it is declared to the end of the block in which the declaration is made.
For example in the following procedure the
constants X_ITEM and Y_ITEM are visible from when they are
declared till the end of the procedure. This is why X_ITEM can be used in
the declaration of Y_ITEM (we could not do the reverse, or at least not without first
reordering the declarations).
procedure SUM_AND_PROD is
X_ITEM : constant := 2;
Y_ITEM : constant := X_ITEM*2;
begin
PUT(X_ITEM+Y_ITEM);
NEW_LINE;
PUT(X_ITEM*Y_ITEM);
NEW_LINE;
end SUM_AND_PROD;
|
[B] A data item declared within a block cannot be seen from outside that block, and
is referred to as local data item, i.e. local to a block.
Consider the following example program (Nesting illustrated in diagram to right):
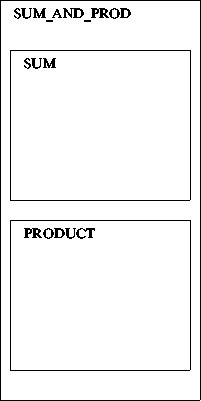
with CS_IO;
use CI_IO;
procedure SUM_AND_PROD is
X_ITEM : constant := 2;
Y_ITEM : constant := X_ITEM*2;
----------------------------------------------------
procedure SUM(P_ITEM, Q_ITEM : INTEGER) is
TOTAL : INTEGER ;
begin
TOTAL := P_ITEM + Q_ITEM;
PUT(TOTAL);
NEW_LINE;
end SUM;
----------------------------------------------------
procedure PRODUCT(S_ITEM, T_ITEM : INTEGER) is
PROD : INTEGER ;
begin
PROD := S_ITEM * T_ITEM;
PUT(PROD);
NEW_LINE;
end PRODUCT;
----------------------------------------------------
begin
SUM(X_ITEM,Y_ITEM);
PRODUCT(X_ITEM,Y_ITEM);
end SUM_AND_PROD;
|
The data items P_ITEM, Q_ITEM and TOTAL are local to the
SUM procedure (block), while data items S_ITEM, T_ITEM and PROD are local to
the PRODUCT procedure (block).
[C] Anything declared in a block is also visible in all enclosed blocks.
Thus in the following example program (nesting given ti the right) the
data item ANSWER is visible to the two
enclosed blocks (SUM and product).

with CS_IO;
use CI_IO;
procedure SUM_AND_PROD is
X_ITEM : constant := 2;
Y_ITEM : constant := X_ITEM*2;
----------------------------------------------------
procedure SUM_AND_PRODUCT(P_ITEM,
Q_ITEM: INTEGER) is
ANSWER : INTEGER;
--------------------------------------------
procedure SUM(A_ITEM,B_ITEM: INTEGER) is
begin
ANSWER := A_ITEM + B_ITEM;
end SUM;
--------------------------------------------
procedure PRODUCT(C_ITEM,D_ITEM: INTEGER) is
begin
ANSWER := C_ITEM * D_ITEM;
end PRODUCT;
--------------------------------------------
begin
SUM(P_ITEM,Q_ITEM);
PUT(ANSWER);
NEW_LINE;
PRODUCT(P_ITEM,Q_ITEM);
PUT(ANSWER);
NEW_LINE;
end SUM_AND_PRODUCT;
----------------------------------------------------
begin
SUM_AND_PRODUCT(X_ITEM,Y_ITEM);
end SUM_AND_PROD;
|
Global data items (items which are required to be visible from anywhere in a program)
must be declared within the outermost block, i.e. level 1 or the global level. Note that where ever possible use of
global data items should be avoided
as the values associated with these items can easily be altered erroneously.
[D] Several data items with the same name cannot be used in the same
block, however several items with the same name can be declared in "different" blocks.
In this case the declared items
have nothing to do with one another (other than sharing the same name). For example:
with CS_IO;
use CI_IO;
procedure SUM_AND_PROD is
X_ITEM : constant := 2;
Y_ITEM : constant := X_ITEM*2;
----------------------------------------------------
procedure SUM(P_ITEM, Q_ITEM : INTEGER) is
TOTAL : INTEGER;
begin
TOTAL := P_ITEM + Q_ITEM;
PUT(TOTAL);
NEW_LINE;
end SUM;
----------------------------------------------------
procedure PRODUCT(P_ITEM, Q_ITEM : INTEGER) is
TOTAL : INTEGER;
begin
TOTAL := P_ITEM * Q_ITEM;
PUT(TOTAL);
NEW_LINE;
end PRODUCT;
----------------------------------------------------
begin
SUM(X_ITEM,Y_ITEM);
PRODUCT(X_ITEM,Y_ITEM);
end SUM_AND_PROD;
|
Here the repeated declarations of the data items TOTAL P_ITEM and Q_ITEM define data
items that are completely independent (despite the shared name).
[E]
Where a name is used in a block and reused in a sub-block nested within it, the sub -block declaration will
override the super-block declaration during the life time of the sub-block.
This is referred to as
occlusion. The identifier which is hidden because of the inner declaration is said to be occluded. This is the case in the following example:
with CS_IO;
use CI_IO;
procedure SUM_AND_PROD is
X_ITEM : constant := 2;
Y_ITEM : constant := X_ITEM*2;
----------------------------------------------------
procedure SUM(P_ITEM, Q_ITEM : INTEGER) is
X_ITEM : INTEGER;
begin
X_ITEM := P_ITEM + Q_ITEM;
PUT(X_ITEM);
NEW_LINE;
end SUM;
----------------------------------------------------
procedure PRODUCT(X_ITEM, Y_ITEM : INTEGER) is
PROD : INTEGER;
begin
PROD := X_ITEM * Y_ITEM;
PUT(PROD);
NEW_LINE;
end PRODUCT;
----------------------------------------------------
begin
SUM(X_ITEM,Y_ITEM);
PRODUCT(X_ITEM,Y_ITEM);
end SUM_AND_PROD;
|
Here the global data item, X_ITEM is occluded in the SUM and PRODUCT procedures.
The data item Y_ITEM is occluded in the PRODUCT procedure in a similar way.

Interactive Ada nesting diagram.
3.2. C SCOPE RULES
The scope of a data item in C is governed by its storage class.
Generally data items belong to one of two storage classes:
- extern (external) - used to define global variables visible throughout a program.
- auto (automatic) - used to define local variables (including formal parameters to functions)
visible only inside a procedure (block). Local variables exist only while the block of code in
which they are declared is executing. Note that where a local variable and a global variable share the same
name the local variable overrides the global variable.
C also supports two other storage classes static and register, but these will not be discussed
further here.
C Example:
With reference to the given C program:
GLOBAL PARAMETERS
- The variables a and b and the type TEMPERATURE
are declared externally to any procedure (function) and are thus
global variables visible from any where within the program.
- Variables declared within a procedure have a duration equivalent to the lifetime of the procedure - they are
local to the procedure.
- If a global variable name is reused in a procedure declaration the
value associated with this redeclaration will last
for the duration of
the procedure, after which the value associated with the name will revert back to the original
global
value.
4. MODULES
A number of related declarations of types, variables and
routines can be grouped together into a module, also sometimes referred to as a package (Ada) or task.
The concept of modules (and modular programming) appeared in 1970's in response to the increasing size of programs.
Modules comprise a specification part and a body part.
The specification part contains a description of the interface and
the body the code that implements the interface.
The specification part is accessible to the user, the implementation part is
"hidden" (information hiding).
4.1. CREATING AN ADA PACKAGE
Ada packages comprise two parts:
- A specification part which gives the user information about the resources contained and how they are used.
- A package body that details the resources
Note that the body is not visible to the user.
Example:
Creating the package:
package TIMES_TWO_PKG is
-- SPECIFICATION
function TIMES_TWO (
NUMBER : integer
) return integer;
end TIMES_TWO_PKG ;
-- BODY
package body TIMES_TWO_PKG is
function TIMES_TWO (
NUMBER : integer
) return integer is
begin
return(NUMBER*2);
end ;
end TIMES_TWO_PKG;
|
Incorporating the package into another program:
with CS_IO, TIMES_TWO_PKG;
use CS_IO ;
procedure EXAMPLE is
VALUE: integer:= 4;
DOUBLE: integer:= 0 ;
begin
DOUBLE := TINESTWO.TIMES_TWO(VALUE);
put("VALUE = "); put(VALUE); new_line;
put("DOUBLE = "); put(DOUBLE); new_line;
end EXAMPLE;
|
Compiling:
ICC timestwo.ada
4.2. CREATING A C MODULE
Creating the module:
/* SPECIFICATION */
int timesTwo(int);
/* BODY */
int timesTwo(int value)
{
return(value*2);
}
Incorporating the module into another program:
#include <stdio.h>
void main(void)
{
int value=4;
printf("Two times %d = %d\(n",value,timesTwo(value));
}
|
Compiling:
cc -Aa -c timestwo.c
cc -Aa -c example.c
cc -Aa -o example example.o timestwo.o
4.3. CREATING A C HEADER FILE
Whereas a C module is first compiled to create an object file (a .o file) and later linked into
the main program, a header file is compiled at the same time as the "main" program.
The sequence of activities is as follows - first create a .h file:
int timesTwo(int);
int timesTwo(int x)
{
return(x*2);
}
|
Second, incorporate the .h file into a program:
#include <stdio.h>
#include "timestwo.h"
void main(void)
{
int x=4;
printf("Two times %d = %d\n", x,timesTwo(x));
}
|