
|
Figure 1: Components of a data item (notation after Baron 1977)
DATA |
DATA - "that which is given". A data item has a number of attributes:
The type of a data item also dictates the operations that can be performed on it. For example numeric data types can have the standard mathematical operations performed on them while string data types cannot.
To do anything useful with a data item all the above must be tied together by giving each data item an identifying name (sometimes referred to as a label or an identifier).
It is also useful to adopt some sort of naming convention, for example ending all constant data item names with "const".
Data Items comprise: (1) a name, (2) an address and (3) a value (Figure 1). Knowledge of the data item name allows access to the address which in turn allows access to the value. It is important to distinguish between the different components of a data item.
|
|
Figure 1: Components of a data item (notation after Baron 1977)
Data items can be classified as being either global or local data items, and as being either variables or constants. The nature of a data item is defined through a data declaration.
Bal and Grune (1994) summaris the inter-relationship between the different data item attributes using a diagram of the form presented in Figure 2. The components of the diagram are self explanatory.
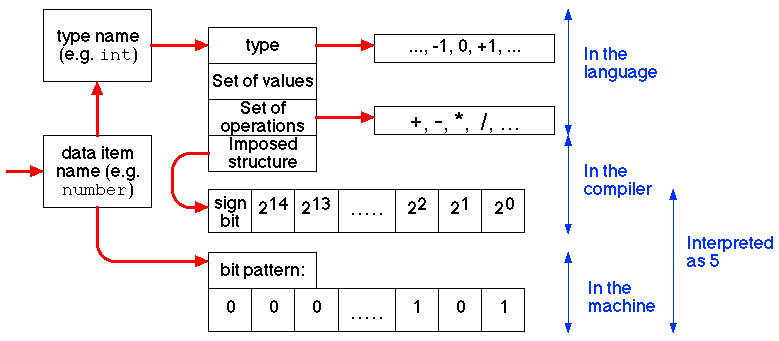
|
Figure 2: The inter-relationship between data item attributes (Bal and Grune 1994)
A data declaration introduces a data item. This is typically achieved by associating the item (identified by a name) with a data type. Examples in Ada, Pascal and C:
NUMBER: integer; number: integer; int number;
Here we have declared a data item called number as an integer. Note that by convention, in Ada and Pascal (which are not case sensative), we distinguish between reserved words and user defined labels by writing one or the other using upper-case characters.
In some Imperative languages we can specify the possible values for a data item, in which case the compiler may deduce the type of a data item according to the nature of these values. Examples in Pascal:
number: 1..10; letter: 'A'..'C';
Here the first item, number, will be considered to be an integer (because the range of possible values for the item are integers); and the second item, letter, will be considered to be a character (because the range of possible values for the item are characters).
Assignment is the process of associating a value with a data item. Usually achieved using an assignment operator. Examples in Ada, Pascal and C:
NUMBER := 2; number := 2; number = 2;
Here we have assigned the value 2 to a data item called "number". Note that the assignment operator in Ada and Pascal is := and in C is =. This is a common distinction between the Algol and C style of programming lanaguage.
Initialisation is then the process of assigning an initial value to a data item. Some imperative languages allow this to be done on declaration (e.g. C and Ada) others do not (e.g. Pascal). Examples in Ada and C:
NUMBER: integer:= 2; int number = 2;
(In Pascal you must first declare a data item and then assign a value to it,
conserquently the concept of inialisation does not exist in Pascal).
Ordering of declarations
In some imperative languages (notably Pascal) declarations must be presented in a certain order, e.g. constants before variables. In Pascal constants (see below) are grouped together in a CONST section, followed by variables grouped together in a VAR section.
Many imperative langauge (Ada and Pascal, but not C) support the concept of multiple assignment where a number of variable can be assigned a value (or values) using a single assignment statement. Examples in Ada:
NUMBER1, NUMBER2 := 2;
In Pascal we do not have to assign the same value to each varaibale when using a multiple assignment statement:
number1, number2 := 2, 4;
In Pascal we can also write:
number1, number2 := number2, number1;
which has the effect of "doing a swap".
In languages such as C, Ada and pascal data declarations are expected to be found at the start of a procedure or function definition (with the exception of C global data items --- see below). Some languages allow declarations to occur anywhere with in procedure or function definition (for example the object oriented languages Java and C++). What ever the case remember that:
Data items have associated with them:
The nature of the life time and visibility of a data item is dictated by what are referred to as scoping rules. In this respect there are two types of data:
It is sometimes desirable to define a data item whose value cannot be changed. Such data items are referred to as constants and are usually indicated by incorporating a predefined key word into the declaration. Examples in Ada and C:
LABEL: constant:= 2; const int label = 2;
Note that in Ada we do not declare the data type of the constanr because this can be deduced from its value. In Pascal we declare constants by grouping then together in a const section:
const label = 2; pi = 3.14159; VAR number integer;
We can think of a constant as a data item comprising only of a name and a value (Figure 3), i.e. no address.
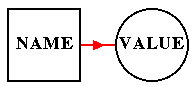
|
Figure 3: A constant data item
However it should be appreciated that what we are doing here is telling the compiler to "flag" the data item as a constant (i.e. we are only instigating software protection). Theoretically we can still change the bit pattern representing the value.
At this stage in the discussion it is appropriate to present a number of example prgrams that feature different kinds of data. The first, Table 1, is a C program that has two global data items, a variable GLOBAL and a constant GLOBAL_CONST. Note that:
The prgram otputs the four data items, performs some (mixed mode) arithmetic, and then outputs the same data items.
#include < stdio.h >
int GLOBAL_VAR = 0;
const int GLOBAL_CONST = 1;
/* Main function */
int main(void) {
int localVar = 2;
const int localConst = 3;
printf("%d, %d, %f, %d\n",GLOBAL_VAR,GLOBAL_CONST,localVar,localConst);
GLOBAL_VAR = GLOBAL_CONST + (localVar*localConst);
printf("%d, %d, %f, %d\n",GLOBAL_VAR,GLOBAL_CONST,localVar,localConst);
}
|
Table 1: C program
The code in Table 2 does exactly the same thing as that presented in Table 1 except that it is written in Ada. Note that:
with TEXT_IO;
use TEXT_IO;
procedure TOP_LEVEL is
package INT_INOUT is new INTEGER_IO(integer);
use INT_INOUT;
GLOBAL_VAR : integer := 0;
GLOBAL_CONST : constant := 1;
--------- SECOND LEVEL PROCEDURE ---------
procedure PROC_1 is
LOCAL_VAR : integer := 2;
LOCAL_CONST : constant := 3;
begin
put(GLOBAL_VAR);
put(", ");
put(GLOBAL_CONST);
put(", ");
put(LOCAL_VAR);
put(", ");
put(LOCAL_CONST);
new_line;
-- Sum
GLOBAL_VAR := GLOBAL_CONST + (LOCAL_VAR*LOCAL_CONST);
-- Output
put(GLOBAL_VAR);
put(", ");
put(GLOBAL_CONST);
put(", ");
put(LOCAL_VAR);
put(", ");
put(LOCAL_CONST);
new_line;
end PROC_1;
---------- TOP LEVEL --------
begin
PROC_1;
end TOP_LEVEL;
|
Table 2: Ada program
Finally Table 3 gives a Pascal program with the same functionality as that presented in Tables 1 and 2. Note here:
program myProg(Output);
{Example program}
const
globalConst = 1;
var
globalVar : integer;
procedure proc1;
{second level procedure}
const
localConst = 3;
var
localVar : integer;
begin {Proc_1}
localVar := 2;
write(globalVar);
write(', ',globalConst);
write(', ',localVar);
writeLn(', ',localConst);
{Sum}
globalVar := globalConst + (localVar*localConst);
{Outwrite}
write(globalVar);
write(', ',globalConst);
write(', ',localVar);
writeLn(', ',localConst);
end; {Proc1}
begin {myProg}
globalVar := 1;
proc1;
end. {myProg}
|
Table 3: Pascal program
Often we use data items in a programme without giving them a name, such data items are referred to as anonymous data items. Examples include (in C):
4 + (5*6) number + (5*6)
Here the arithmetic sub-expression, (5*6), is processed first and the result stored somewhere as a data item which has a value and an address. However it has no name, consequently such a data item is known as an anonymous data item. The significance is that anonymous data items cannot be changes or used again in other parts of a program. Conceptually we can think of an anonymous data item as a data item without a name (Figure 4), consequently we cannot access its address (or its value).

|
Figure 4: An anonymous data item
To summarise the above:
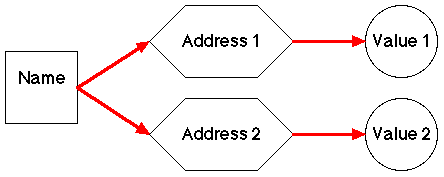
It is sometimes useful, given a particular application, to rename (alias) particular data items, i.e. provide a second access path to it. This is supported by some imperative languages such as Ada (but not C or Pascal). Ada Example:
ITEM: integer = 1; ONE: integer renames ITEM;
Here we have declared a data item ITEM and then allocated a second name (ONE) to the item. Thus, conceptually, renaming creates a data item with more than one name (but only one address and consequently only one value), i.e. we have more than one access route to the address (Figure 5).
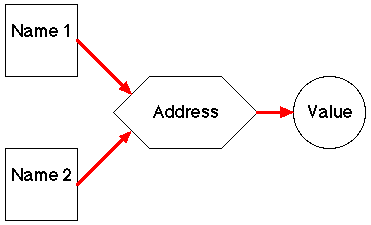
|
Figure 5: Aliasing
It is dangerous to rename variables. Consider the following Ada programme:
with CS_IO; use CS_IO;
procedure RENAME is
ITEM : integer;
ONE : integer renames ITEM;
begin
get(ITEM);
put("ITEM = "); put(ITEM); new_line;
put("ONE = "); put(ONE); new_line; new_line;
ITEM:= ITEM*10;
put("ITEM = "); put(ITEM); new_line;
put("ONE = "); put(ONE); new_line; new_line;
ONE:= ONE*10;
put("ITEM = "); put(ITEM); new_line;
put("ONE = "); put(ONE); new_line;
end RENAME;
The result will be as shon below!
ITEM = 1 ONE = 1 ITEM = 10 ONE = 10 ITEM = 100 ONE = 100
Note that any change made to data item ITEM results in an identical change to data item ONE (and vice versa). This is because both names represent the same data item.
|
Figure 6: Overloading
5 + 3 5 - 3 5.6 + 3.2 5.6 - 3.2
5 + 3.2 5.6 - 3 5.6 + 3 5 - 3.2
Return to imperative home page or continue.
Created and maintained by Frans Coenen. Last updated 03 July 2001